
Live Hand Written Digit Classification
Brief overview of the project
![]()
![]()
![]()
Hand written text classification is one of the basic problems in the field of Machine Learning. There has been so many techniques developed for the task for example ANN, Perceptron modelling and many more. But one of the most common architecture that has been able to perform much better than most of the other ML architectures is CNN. Convolutional Neural Networks, commonly known as CNN, are very popular when it comes to pattern recognition and image analysis because of its ease of use and the results that they produce.
- Demonstrate the working of CNN and its performance
- Identify a digit from an image or live camera
Implementing and Demonstrating CNN:
Here I have built a CNN model using Keras framework. The Keras framework allows us to build a CNN model very easily. It has been demonstrated how a CNN model actaully classifies an image in its respective class or what does a layer in CNN sees when it gets certain images. The details can be checked in my notebook code. The model has been trained using the MNIST data. The data has been obtained from this link. The simple model has reached accuracy of 98.7% and reaches around 99.5% when rotational and linear translational variances are also considered. Although it is true that the data provided is clean and not very difficult for a model to learn it still can be said how good CNNs work when it comes to pattern observations.
Identifying Digits:
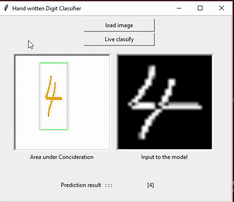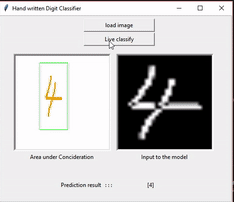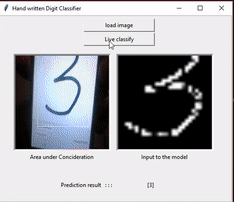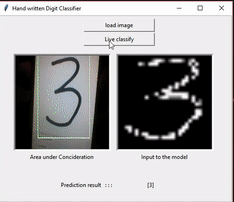
In this section apart from solving the kaggle challenge above I have extended it to finding digits in live videos or images and classifying them. Here the main objective is - given a frame containing a number, identifying and correctly cropping and resizing it so that it can be provided into the trained classifier model to get the output. So to perform the task the following flow is being used:
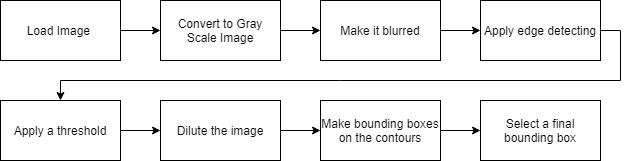
A sample of how the above images look at each stage of processing:
 Image after converting to Gray Scale. |  Bluring the image. |  Applying edge detector on the blurred image. |
 Applying a threshold to the previous image. |  Diluting image. | 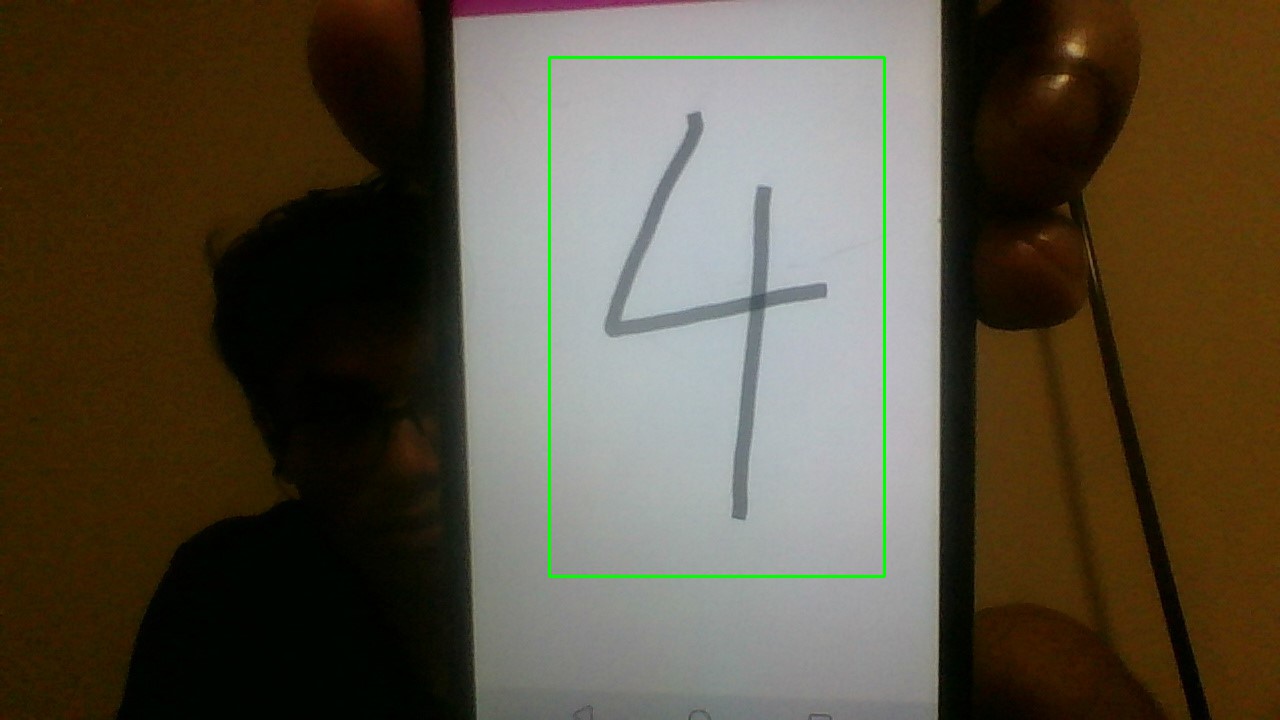 Final Bounding box. |
So, once the image is extracted we feed it into the pretrained model, generated using the previous mentioned point, and get the output. As we can see even if we move the live image it still can extract the number by its own. For the ease of demonstration I have made a GUI application that does the mentioned work. Just to see the working I have put the recording of the same.