
Titanic Survival Prediction
Brief overview of the project
![]()
![]()
![]()
Problem statement:
This code is for the Kaggle contest given in this link. In this problem, given a training set containing information about people on the titanic and if they eventually survived or not, I have to predict the same for the test samples.
Work done:
As it sounds it is a simple classification problem but as it can be seen while working out the data provided is not the perfect data and there are missing entries along or with too many features. All these has been analyzed using basic techniques. Feature engineering has to be done to select the good features and the missing values are filled using certain logic which is explained well in the notebook file.
Once the dataset is cleaned and the missing values are filled, then I proceed to the classifying the model. Various popular classifiers are used to predict the outcome. The model that gave the best result was used as the final model to predict the final results. Below is a comparative chart of the various classifiers that are used to compare their performance.
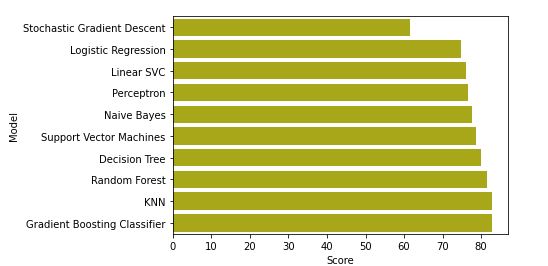
Conclusion:
As it can be seen above that Gradient Boosting Classifier, Random Forest and KNN are giving much better accuracy compared to the other classifiers we could use any of these 3 for the final predictions. Although it cannot be predicted which model will finally give the best results, it can be said that these 3 would perform better than others.However, the classifier itself is only a partial part because the way the features are generated and used plays a very important role in the final results.
For details of the code and how the above plot has been attained with proper explanation check my Jupyter Notebook File here.